How to make machines learn massive number of regression tasks efficiently and accurately
Abstract
Many real-world large-scale regression problems can be formulated as Multi-task Learning (MTL) problems with a massive number of tasks, as in retail and transportation domains. However, existing MTL methods still fail to offer both the generalization performance and the scalability for such problems. Scaling up MTL methods to problems with a tremendous number of tasks is a big challenge. Here, we propose a novel algorithm, named Convex Clustering Multi-Task regression Learning (CCMTL), which integrates with convex clustering on the -nearest neighbor graph of the prediction models. Further, CCMTL efficiently solves the underlying convex problem with a newly proposed optimization method. CCMTL is accurate, efficient to train, and empirically scales linearly in the number of tasks. On both synthetic and real-world datasets, the proposed CCMTL outperforms seven state-of-the-art (SoA) multi-task learning methods in terms of prediction accuracy as well as computational efficiency. On a real-world retail dataset with tasks, CCMTL requires only around seconds to train on a single thread, while the SoA methods need up to hours or even days.
Introduction
Multi-task learning (MTL) is a branch of machine learning that aims at exploiting the correlation among tasks. To achieve this, the learning of different tasks is performed jointly. It has been shown that learning task relationships can transfer knowledge from information-rich tasks to information-poor tasks [11] so that overall generalization error can be reduced. With this characteristic, MTL has been successfully applied in use cases ranging from Transportation [3] to Biomedicine [9].
In real-world regression applications, the number of tasks can be tremendous. For instance, in the retail market, shops’ owners would like to forecast the sales amount of all the products based on the historical sales information and external factors. For a typical shop, there are thousands of products, where each product can be modeled as a separate regression task. In addition, if we consider large retail chains, where the number of shops in a given region is in the order of hundreds, the total number of learning tasks easily grows up to hundreds of thousands. A similar scenario can also be found in other applications, e.g. demand prediction in transportation, where each task is one public transport station demand in a city at a certain time per line. Here, at least tens of thousands of tasks are expected.
In all these scenarios, MTL approaches that exploit relationships among tasks are appropriate. Unfortunately most of existing SoA multi-task learning methods cannot be applied, because either they are not able to cope with task heterogeneity or are too computationally expensive, scaling super-linearly in the number of tasks.
To tackle these issues, this paper introduces a novel algorithm, named Convex Clustering Multi-Task regression Learning (CCMTL). It integrates the objective of convex clustering[5] into the multi-task learning framework. CCMTL is efficient with linear runtime in the number of tasks, yet provides accurate prediction. The detailed contributions of this paper are fourfold:
- 1.
Model: A new model for multi-task regression that integrates with convex clustering on the -nearest neighbor graph of the prediction models;
- 2.
Optimization Method: A new optimization method for the proposed problem that is proved to converge to the global optimum;
- 3.
Accurate Prediction: Accurate predictions on both synthetic and real-world datasets in retail and transportation domains which outperform eight SoA multi-task learning methods;
- 4.
Efficient and Scalable Implementation: An efficient and linearly scalable implementation of the algorithm. On a real-world retail dataset with tasks, the algorithm requires only around seconds to terminate, whereas SoA methods typically need up to hours or even days.
For proofs and additional details we refer to the original paper [4]111https://www.aaai.org/ojs/index.php/AAAI/article/view/4262/4140.
The Proposed Method
Let us consider a dataset with regression tasks for each task . consists of samples and features, while is the target for task . There are totally samples, where . We consider linear models in this paper. Let , where represent the weight vector for task .
Model
Base on the intuition of convex clustering, CCMTL solves the following problem
| (1) |
where is a regularization parameter and is the -nearest neighbor graph on the prediction models learned independently for each task.
Optimization
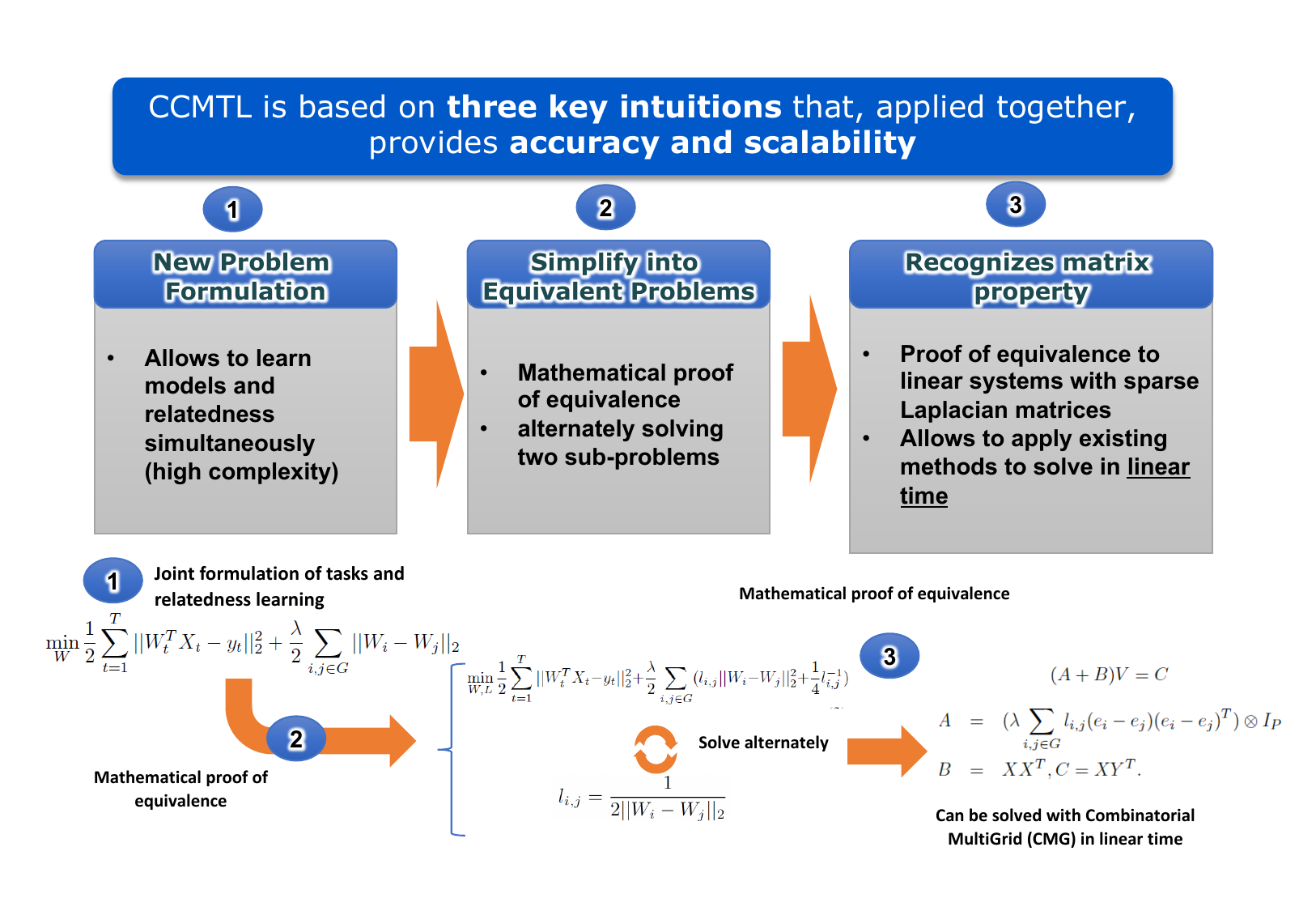
Fig.1 shows graphically the key intuitions of CCMTL for solving problem with massive number of tasks and high accuracy.
First we introduce an auxiliary variable for each connection between node and in graph , , and we form the following new problem:
| (2) |
Intuitively, Problem (2) learns the weights for the squared norm regularizer as in Graph regularized Multi-task Learning (SRMTL) [12]. With noisy edges, squared norm forces uncorrelated tasks to be close, while norm is more robust which is confirmed for MTL in the experimental section.
In order to solve Problem (2), let us define as a block diagonal matrix
define as a row vector
and define as a column vector , is an indicator vector with the th element set to and others and is an identity matrix of size . Setting the derivative of Problem (2) with respect to to zero, the optimal solution of can be obtained by solving the following linear system:
| (4) |
where , , , and is derived by reshaping .
Would Alg.1 converge to the optimal solution of the orginal problem? The following theorem answer the question.
Efficient and Scalable Implementation
CCMTL is summarized in Algorithm 1. Firstly, it initializes the weight vector by performing Linear Regression on each task separately. Then, it constructs the -nearest neighbor graph on based on the Euclidean distance. Finally, the optimization problem is solved by iteratively updating and until convergence.
Solving the linear system in Eq. (4) involves inverting a matrix of size , where is the number of features and is the number of tasks. Direct inversion will lead to cubic computational complexity, which will not scale to a large number of tasks. However, there are certain properties of and in Eq. (4) that can be used to derive efficient implementation.
Theorem 3.
and in Eq. (4) are both Symmetric and Positive Semi-definite and is a Laplacian matrix.
The runtime of CCMTL consists of threefold: 1) Initialization of , 2) -nearest neighbor graph construction, and 3) optimization of Problem (2). Clearly, initialization of by linear regression is efficient and scales linearly on the number of tasks . -nearest neighbor graph construction naively scales quadratically to , but approximate solver has complexity of . Solving the linear system in Eq. (4) exhibit linear complexity in .

Experiments
Comparison Methods and Datasets
We compare our method CCMTL with several SoA methods. As baselines, we compare with Single-task learning (STL), which learns a single model by pooling together the data from all the tasks and Independent task learning (ITL), which learns each task independently. We further compare to multi-task feature learning method: Joint Feature Learning (L21) [1] and low-rank methods: Trace-norm Regularized Learning (Trace) [8] and Robust Multi-task Learning (RMTL) [2]. We also compare to the other five clustering approaches: CMTL[7], FuseMTL[13], SRMTL[12] and two recently proposed models BiFactorMTL and TriFactorMTL[10].
| Name | Samples | Features | Num Tasks |
|---|---|---|---|
| Sales | 34062 | 5 | 811 |
| Ta-Feng | 2619320 | 5 | 23812 |
| Alighting | 33945 | 5 | 1926 |
| Boarding | 33945 | 5 | 1926 |
We employ both synthetic and real-world datasets. Table 1 shows their statistics.
Results and Discussion
| Sales | Ta-Feng | |||
| RMSE | Time(s) | RMSE | Time(s) | |
| STL | 2.861 (0.02) | 0.1 | 0.791 (0.01) | 0.2 |
| ITL | 3.115 (0.02) | 0.1 | 0.818 (0.01) | 0.4 |
| L21 | 3.301 (0.01) | 11.8 | 0.863 (0.01) | 831.2 |
| Trace | 3.285 (0.21) | 10.4 | 0.863 (0.01) | 582.3 |
| RMTL | 3.111 (0.01) | 3.4 | 0.833 (0.01) | 181.5 |
| CMTL | 3.088 (0.01) | 43.4 | - | |
| FuseMTL | 2.898 (0.01) | 4.3 | 0.764 (0.01) | 8483.3 |
| SRMTL | 2.854 (0.02) | 10.3 | - | |
| BiFactor | 2.882 (0.01) | 55.7 | - | |
| TriFactor | 2.857 (0.04) | 499.1 | - | |
| CCMTL | 2.793 (0.01) | 1.8 | 0.767 (0.01) | 35.3 |
Table 2 depicts the results on two retail datasets: Sales and Ta-Feng; it also depicts the time required (in seconds) for the training using the best found parametrization for each method. Here of samples are used for training. The best runtime for MTL methods is shown in boldface. Tasks in these two datasets are, again, rather homogeneous, therefore, the baseline STL has a competitive performance and outperforms many MTL methods. STL outperforms ITL, L21, Trace222 The hyperparameters searching range for L21 and Trace are shifted to for Ta-Feng dataset to get reasonable results., RMTL, CMTL, FuseMTL, SRMTL, BiFactor, and TriFactor on the Sales dataset, and outperforms ITL, L21, Trace and RMTL on the Ta-Feng data333 We set a timeout at . CMTL, SRMTL, BiFactor, and TriFactor did not return the result on this timeout for the Ta-Feng dataset.. CCMTL is the only method that performs better (also statistically better) than STL on both data sets; it also outperforms all MTL methods (with statistical significance) on both data sets, except for FuseMTL which performs slightly better than CCMTL only on the Ta-Feng data. CCMTL requires the smallest runtime in comparison with the competitor MTL algorithms. On Ta-Feng dataset, CCMTL requires only around seconds, while the SoA methods need up to hours or even days.
| Alighting | Boarding | |||
| RMSE | Time(s) | RMSE | Time(s) | |
| STL | 3.073 (0.02) | 0.1 | 3.236 (0.03) | 0.1 |
| ITL | 2.894 (0.02) | 0.1 | 3.002 (0.03) | 0.1 |
| L21 | 2.865 (0.04) | 14.6 | 2.983 (0.03) | 16.7 |
| Trace | 2.835 (0.01) | 19.1 | 2.997 (0.05) | 17.5 |
| RMTL | 2.985 (0.03) | 6.7 | 3.156 (0.04) | 7.1 |
| CMTL | 2.970 (0.02) | 82.6 | 3.105 (0.03) | 91.8 |
| FuseMTL | 3.080 (0.02) | 11.1 | 3.243 (0.03) | 11.3 |
| SRMTL | 2.793 (0.02) | 12.3 | 2.926 (0.02) | 14.2 |
| BiFactor | 3.010 (0.02) | 152.1 | 3.133 (0.03) | 99.7 |
| TriFactor | 2.913 (0.02) | 282.3 | 3.014 (0.03) | 359.1 |
| CCMTL | 2.795 (0.02) | 4.8 | 2.928 (0.03) | 4.1 |
Table 3 depicts the results on the Transportation datasets, using two different target attributes (alighting and boarding); again, the runtime is presented for the best-found parametrization, and the best runtime achieved by the MTL methods are shown in boldface.
Figure 2 shows the recorded runtime in seconds while presenting the number of tasks in the log-scale. As can be seen, CMTL, MTFactor, and TriFactor were not capable to process 40k tasks in less than 24 hours, therefore, they were stopped (the extrapolation for the minimum needed runtime can be seen as a dashed line). FuseMTL, SRMTL, L21, and Trace tend to show a super-linear growth of the needed runtime in the log-scale. Both CCMTL and RMTL show constant behavior in the number of tasks, where only around and seconds are needed for the dataset with tasks respectively. CCMTL is the fastest method among all the MTL competitors.
Conclusion
In this paper, we study the multi-task learning problem with a massive number of tasks. We integrate convex clustering into the multi-task regression learning problem that captures tasks’ relationships on the -NN graph of the prediction models. Further, we present an approach CCMTL that solves this problem efficiently and is guaranteed to converge to the global optimum. Extensive experiments show that CCMTL makes a more accurate prediction, runs faster than SoA competitors on both synthetic and real-world datasets, and scales linearly in the number of tasks. CCMTL will serve as a method for a wide range of large-scale regression applications where the number of tasks is tremendous. In the future, we will explore the use of the proposed method for online learning and high-dimensional problem.
Acknowledgments
The authors would like to thank Luca Franceschi for the discussion of the paper and the anonymous reviewers for their helpful comments and Prof. Yiannis Koutis for sharing the implementation of CMG.
References
- [1] (2007)Multi-task feature learning. In NIPS, pp. 41–48. Cited by: Comparison Methods and Datasets.
- [2] (2011)Integrating low-rank and group-sparse structures for robust multi-task learning. In KDD, pp. 42–50. Cited by: Comparison Methods and Datasets.
- [3] (2017)Situation aware multi-task learning for traffic prediction. In ICDM, pp. 81–90. Cited by: Introduction.
- [4] (2019)Efficient and Scalable Multi-task Regression on Massive Number of Tasks. In The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Note: Comment: Accepted at AAAI 2019External Links: LinkCited by: Introduction.
- [5] (2011)Clusterpath an algorithm for clustering using convex fusion penalties. In ICML, Cited by: Introduction.
- [6] (2011)Combinatorial preconditioners and multilevel solvers for problems in computer vision and image processing. Computer Vision and Image Understanding115 (12), pp. 1638 – 1646. External Links: ISSN 1077-3142Cited by: 1.
- [7] (2009)Clustered multi-task learning: a convex formulation. In NIPS, pp. 745–752. Cited by: Comparison Methods and Datasets.
- [8] (2009)An accelerated gradient method for trace norm minimization. In ICML, pp. 457–464. Cited by: Comparison Methods and Datasets.
- [9] (2018)Multi-target drug repositioning by bipartite block-wise sparse multi-task learning. BMC systems biology12 (4), pp. 55. Cited by: Introduction.
- [10] (2017)Co-clustering for multitask learning. ICML. Cited by: Comparison Methods and Datasets.
- [11] (2014)A regularization approach to learning task relationships in multitask learning. ACM Transactions on Knowledge Discovery from Data (TKDD)8 (3), pp. 12. Cited by: Introduction.
- [12] (2011)Malsar: multi-task learning via structural regularization. Arizona State University21. Cited by: Optimization, Comparison Methods and Datasets.
- [13] (2012)Modeling disease progression via fused sparse group lasso. In KDD, pp. 1095–1103. Cited by: Comparison Methods and Datasets.