LDS: a bilevel approach to infer sparse and discrete dependency structures for relational learning
Abstract
Graph neural networks (GNNs) are a popular class of machine learning models whose major advantage is their ability to incorporate a sparse and discrete dependency structure between data points. Unfortunately, GNNs can only be used when such a graph-structure is available. In practice, however, real-world graphs are often noisy and incomplete or might not be available at all. With this work, we propose to jointly learn the graph structure and the parameters of graph convolutional networks (GCNs) by approximately solving a bilevel program that learns a discrete probability distribution on the edges of the graph. This allows one to apply GCNs not only in scenarios where the given graph is incomplete or corrupted but also in those where a graph is not available. We conduct a series of experiments that analyze the behavior of the proposed method and demonstrate that it outperforms related methods by a significant margin.
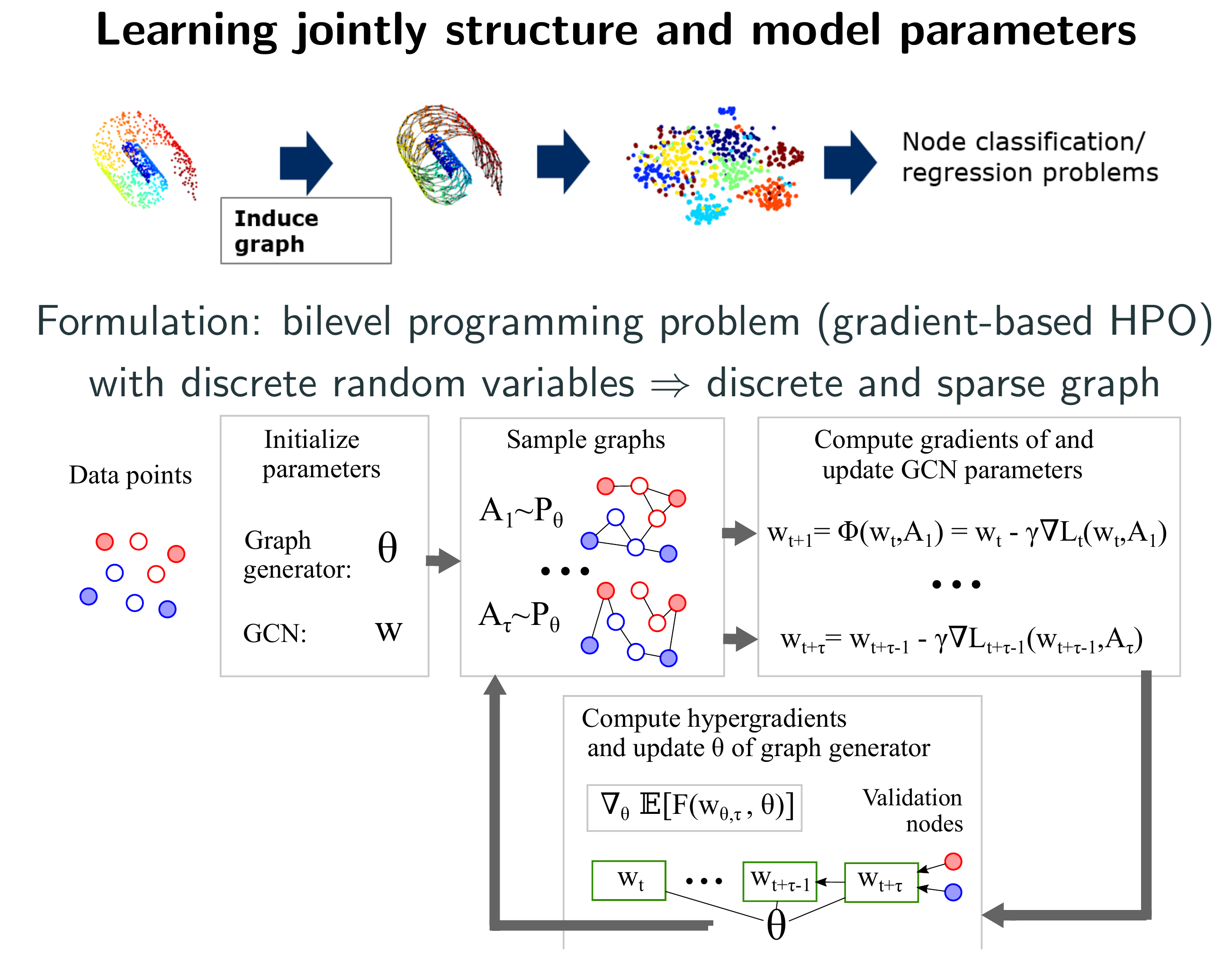
Introduction
Relational learning is concerned with methods that cannot only leverage the attributes of data points but also their relationships. Diagnosing a patient, for example, not only depends on the patient’s vitals and demographic information but also on the same information about their relatives, the information about the hospitals they have visited, and so on. Relational learning, therefore, does not make the assumption of independence between data points but models their dependency explicitly. Graph neural networks (GNNs) [13] are one class of algorithms that are able to incorporate sparse and discrete dependency structures between data points, encoded as graphs.
While a graph structure is available in some domains, in others it has to be inferred or constructed. A possible approach is to first create a -nearest neighbor (NN) graph based on some measure of similarity between data points [12, 14]. A major shortcoming of this approach, however, is that the efficacy of the resulting models hinges on the choice of and, more importantly, on the choice of a suitable similarity measure over the input features. In any case, the graph creation and parameter learning steps are independent and require heuristics and trial and error.
With LDS (Learning Discrete Structures) we follow a different route with the aim of learning discrete and sparse dependencies between data points while simultaneously training the parameters of graph convolutional networks (GCN) [8], a class of GNNs which learn node representations by passing and aggregating messages between neighboring nodes. We propose to learn a generative probabilistic model for graphs, samples from which are used both during training and at prediction time. Edges are modelled with random variables whose parameters are treated as hyperparameters in a bilevel learning framework [6].
LDS is the first method to simultaneously learn the graph and the parameters of a GNN for semi-supervised classification without any form of supervision on the connectivity paths222 This is in contrast to most link-prediction approaches [9, 11]., significantly broadening the range of successful application scenarios of graph neural models. Furthermore, in developing LDS we adapt gradient-based hyperparameter optimization (HPO) to work for a class of discrete hyperparameters, which might be of independent interest.
For details and extended results we refer to the original paper [7], presented at ICML 2019, Long Beach, US.
Jointly Learning the Structure and the Model Parameters
We frame the problem of learning a dependency structure between data points while simultaneously training a GNN as a bilevel programming problem333 Bilevel programs are optimization problems which arise often in hyperparameter optimization and meta-learning, where a set of variables occurring in the (outer) objective function are constrained to be an optimal solution of another (inner) optimization problem. See [4] for an overview and [6] for applications in machine learning. whose outer variables are the parameters of a generative probabilistic model for graphs and inner variables are the parameters of the GNN model. We then develop a practical algorithm based on truncated reverse-mode algorithmic differentiation [16] and hypergradient estimation to approximately solve the resulting problem.
Neural Models for Processing Graph-based Data
GNNs have two inputs: first, a feature matrix where is the number of different node features and is the total number of nodes, second, a graph with adjacency matrix . Depending on the particular downstream application of interest, GNNs may have different outputs; we address node level semi-supervised classification problems, whereby the task is to learn a function that predicts node labels in a given set (e.g. topics of a scientific paper). An example of such type of models, proposed by [8], is the following two hidden layer graph convolutional network (GCN) that computes the class probabilities as
| (1) |
where are the model parameters. The process of learning from a small subset of training nodes (for which the ground truth label is known) is most often cast to an optimization problem of the form
| (2) |
where is a point-wise loss function, and is a regularizer.
Missing or Incomplete Graph
Now, let us suppose that the information about the true adjacency matrix is missing or incomplete. Since, ultimately, we are interested in finding a model that minimizes the generalization error, we assume the existence of a second subset of instances with known target, (the validation set), from which we can estimate the generalization error. Hence, we propose to find that minimizes the function
| (3) |
where is the minimizer, assumed unique, of for a fixed adjacency matrix. We can then consider Equations (2) and (3) as the inner and outer objective of a mixed-integer bilevel programming problem where the outer objective aims to find an optimal discrete graph structure and the inner objective the optimal parameters of a GCN given a graph.
Introducing a Simple Generative Model
The resulting bilevel problem is intractable to solve exactly even for small graphs due to its high dimensional combinatorial nature. To circumvent this difficulty we introduce a generative model and reformulate the bilevel program in terms of the (continuous) parameters of the resulting distribution over discrete graphs. Specifically, we propose to model each edge with a Bernoulli random variable. Let be the convex hull of the set of all adjacency matrices for nodes. By modeling all possible edges as a set of mutually independent Bernoulli random variables with parameter matrix we can sample graphs as . Eqs. (2) and (3) can then be replaced by
| (4) | |||
| (5) |
where we take the expectation of the objectives over graph structures. In this way both the inner and the outer objectives become continuous and smooth functions of the Bernoulli parameters.
Structure Learning via Hypergradient Descent
The bilevel problem given by Eqs. (4)-(5) is still challenging to solve efficiently. This is because the solution of the inner problem is not available in closed form for GCNs; and the expectations are intractable to compute exactly444 This is different than e.g. model free reinforcement learning, where the objective function is usually unknown, depending in an unknown way from the action and the environment.. We now discuss a practical algorithm to approach the problem. Regarding the inner problem (5), we can choose a tractable approximate learning dynamics such as stochastic555 The stochasticity arises from the graph distribution. gradient descent (SGD) [3],
| (6) |
where is a learning rate and is drawn at each iteration.
Let be an approximate minimizer of (where may depend on ). We now need to compute an estimator for the hypergradient:
| (7) |
We can swap gradient and expectation operators since is finite and we assume bounded. Next, we use the so-called straight-through estimator [2] and set (which would be a.e. otherwise) and propagate the gradient through (portions of) the learning dynamics to compute [10, 5]. Finally, we take the single sample Monte Carlo estimator of (7) to update the parameters with projected gradient descent on the unit hypercube.
A sketch of the method is presented in Algorithm Structure Learning via Hypergradient Descent, where inputs and operations in squared brackets are optional.

The resulting model
The expected output of a GCN trained with LDS is
| (8) |
which can be cheaply estimated in an unbiased manner as
| (9) |
where is the number of samples we wish to draw. Given the parametrization of the graph generator with Bernoulli variables, one can sample a new graph in . Sampling from a large number of Bernoulli variables, however, is highly efficient, trivially parallelizable, and possible at a rate of millions per second.
Learning discrete distributions has a computational advantage over dense graphs if the sampled graphs are sparse enough: indeed for GCNs computing has a cost of , opposed to for a fully connected graph, where is the expected number of edges, and is the dimension of the weights. Another advantage of using a graph-generative model is that we can interpret it probabilistically which is not the case when learning a dense adjacency matrix.
Experiments
We conducted two series of experiments to empirically validate LDS.
- •
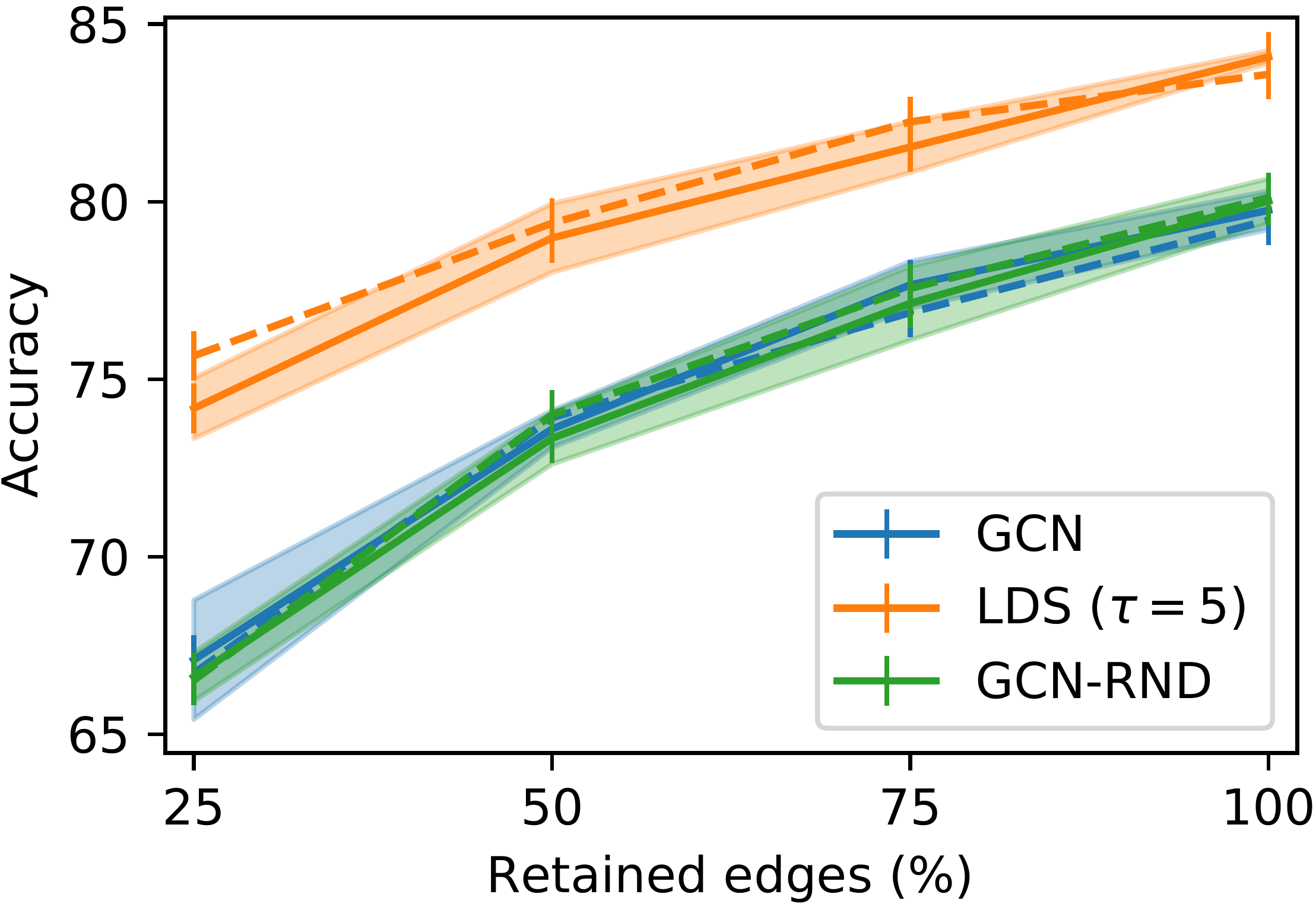
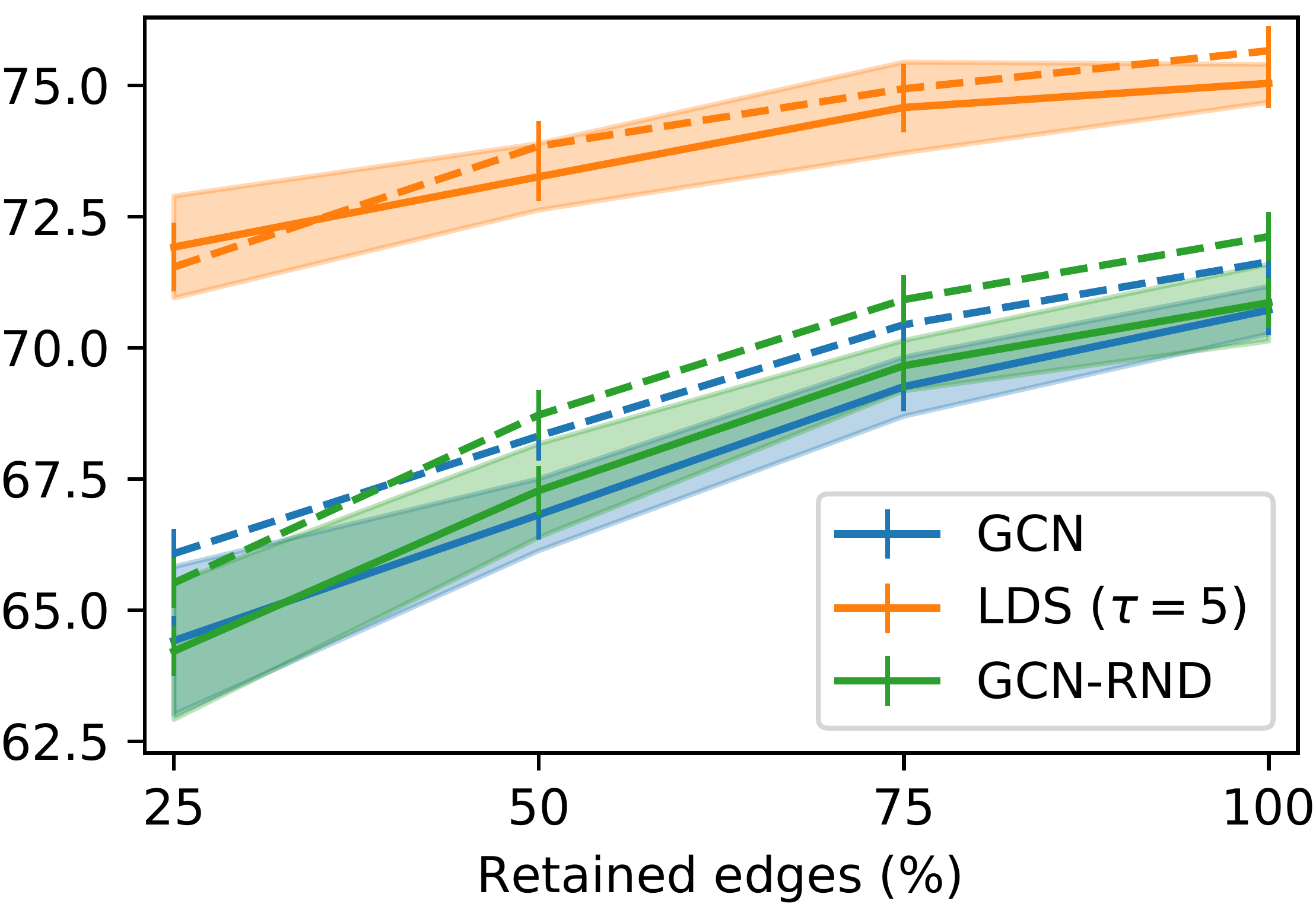
First we measured the ability of LDS of recovering and completing dependency structures on node classification problems where a graph structure is available but where a certain fraction of edges is missing. We compare LDS to vanilla GCNs, and to a “control” method (GCN-RND) where we randomly add edges according to a fix, but validated, probability (Figure 2, top). We use Cora and Citeseer datasets where nodes represent scientific articles and edges represent citations between articles. The classification tasks consist in predicting the topic of each paper.
- •
Second, we validated our hypothesis that LDS can achieve competitive results on semi-supervised classification problems for which a graph is not available. To this end, we compared on several datasets LDS to a number of existing semi-supervised classification approaches, supervised learning baselines and various reasonable variants of LDS, such as one where the structure is given by a -NN affinity graphs extracted from the dataset (Table 1).
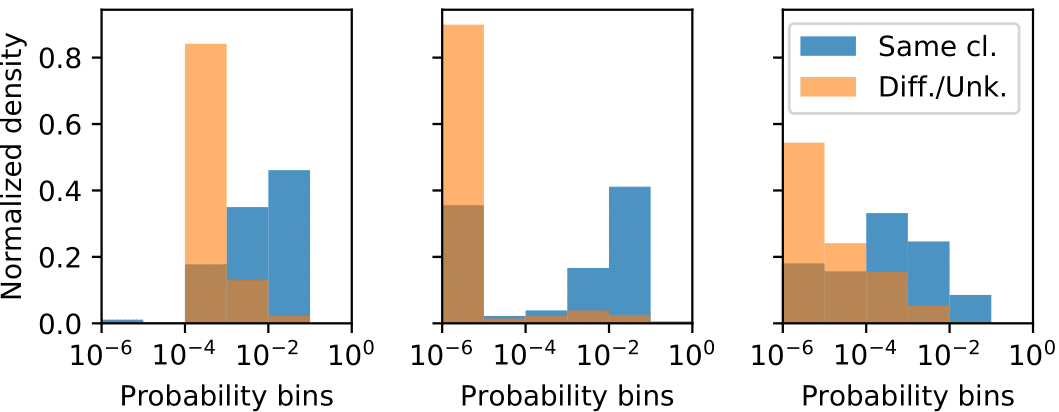
We further showed that the learned graph generative model capture to a certain extent meaningful edge probability distributions, even when a large fraction of edges is missing (Figure 2, bottom).
LDS was implemented in TensorFlow
 |  |
 | |
A Brief Discussion of the Results
| Wine | Cancer | Digits | Citeseer | Cora | 20news | FMA | |
| LogReg | 92.1 (1.3) | 93.3 (0.5) | 85.5 (1.5) | 62.2 (0.0) | 60.8 (0.0) | 42.7 (1.7) | 37.3 (0.7) |
| Linear SVM | 93.9 (1.6) | 90.6 (4.5) | 87.1 (1.8) | 58.3 (0.0) | 58.9 (0.0) | 40.3 (1.4) | 35.7 (1.5) |
| RBF SVM | 94.1 (2.9) | 91.7 (3.1) | 86.9 (3.2) | 60.2 (0.0) | 59.7 (0.0) | 41.0 (1.1) | 38.3 (1.0) |
| RF | 93.7 (1.6) | 92.1 (1.7) | 83.1 (2.6) | 60.7 (0.7) | 58.7 (0.4) | 40.0 (1.1) | 37.9 (0.6) |
| FFNN | 89.7 (1.9) | 92.9 (1.2) | 36.3 (10.3) | 56.7 (1.7) | 56.1 (1.6) | 38.6 (1.4) | 33.2 (1.3) |
| LP | 89.8 (3.7) | 76.6 (0.5) | 91.9 (3.1) | 23.2 (6.7) | 37.8 (0.2) | 35.3 (0.9) | 14.1 (2.1) |
| ManiReg | 90.5 (0.1) | 81.8 (0.1) | 83.9 (0.1) | 67.7 (1.6) | 62.3 (0.9) | 46.6 (1.5) | 34.2 (1.1) |
| SemiEmb | 91.9 (0.1) | 89.7 (0.1) | 90.9 (0.1) | 68.1 (0.1) | 63.1 (0.1) | 46.9 (0.1) | 34.1 (1.9) |
| Sparse-GCN | 63.5 (6.6) | 72.5 (2.9) | 13.4 (1.5) | 33.1 (0.9) | 30.6 (2.1) | 24.7 (1.2) | 23.4 (1.4) |
| Dense-GCN | 90.6 (2.8) | 90.5 (2.7) | 35.6 (21.8) | 58.4 (1.1) | 59.1 (0.6) | 40.1 (1.5) | 34.5 (0.9) |
| RBF-GCN | 90.6 (2.3) | 92.6 (2.2) | 70.8 (5.5) | 58.1 (1.2) | 57.1 (1.9) | 39.3 (1.4) | 33.7 (1.4) |
| NN-GCN | 93.2 (3.1) | 93.8 (1.4) | 91.3 (0.5) | 68.3 (1.3) | 66.5 (0.4) | 41.3 (0.6) | 37.8 (0.9) |
| NN-LDS | 97.3 (0.4) | 94.4 (1.9) | 92.5 (0.7) | 71.5 (1.1) | 71.5 (0.8) | 46.4 (1.6) | 39.7 (1.4) |
On the incomplete graphs scenarios (Figure 2) LDS achieves competitive results in all settings and shows accuracy gains of up to percentage points. Notably, LDS improves the generalization accuracy of GCN models also when the given graph is that of the respective dataset (100% of edges retained), by learning a handful of additional, helpful, edges. The accuracy of 84.1% and 75.0% for Cora and Citeseer, respectively, exceed all previous state-of-the-art results at the time of publication. The learned graphs are very sparse: e.g. for Cora, on average, less than edges are present.
For semi-supervised classification problems (Table 1), we noted that supervised learning baselines work well on some datasets but fail to provide competitive results on others. The semi-supervised learning baselines LP [17], ManiReg [1] and SemiEmb [15] can only improve the supervised learning baselines on , and datasets, respectively. The results for the GCN with different input graphs show that NN-GCN works well and provides competitive results compared to the supervised baselines on all datasets. NN-LDS significantly outperforms NN-GCN on out of the datasets. In addition, NN-LDS is among the most competitive methods on all datasets and yields the highest gains on datasets that have an underlying graph.
Conclusion
In this work we propose LDS, an algorithm based on bilevel programming that simultaneously learns the graph structure and the parameters of a GNN. The strengths of LDS are its high accuracy gains on typical semi-supervised classification datasets at a reasonable computational cost.
Future research paths may include scaling up method to large datasets by working on mini-batches of nodes; extend LDS to the inductive setting and experimenting with more complex graph generative models. In addition, we hope that suitable variants of LDS algorithm will also be applied to other problems such as neural architecture search or to tune other discrete hyperparameters.
References
- [1] (2006)Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. Journal of Machine Learning Research7, pp. 2399–2434. Cited by: A Brief Discussion of the Results.
- [2] (2013)Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432. Cited by: Structure Learning via Hypergradient Descent.
- [3] (2010)Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010, pp. 177–186. Cited by: Structure Learning via Hypergradient Descent.
- [4] (2007)An overview of bilevel optimization. Annals of operations research153 (1), pp. 235–256. Cited by: footnote 3.
- [5] (2017)Forward and reverse gradient-based hyperparameter optimization. ICML. Cited by: Structure Learning via Hypergradient Descent.
- [6] (2018)Bilevel programming for hyperparameter optimization and meta-learning. ICML. Cited by: Introduction, footnote 3.
- [7] (2019)Learning discrete structures for graph neural networks. In International Conference on Machine Learning, pp. 1972–1982. External Links: LinkCited by: Introduction.
- [8] (2017)Semi-supervised classification with graph convolutional networks. ICLR. Cited by: Introduction, Neural Models for Processing Graph-based Data.
- [9] (2011)Link prediction in complex networks: a survey. Physica A: statistical mechanics and its applications390 (6), pp. 1150–1170. Cited by: footnote 2.
- [10] (2015)Gradient-based hyperparameter optimization through reversible learning. In International Conference on Machine Learning, pp. 2113–2122. Cited by: Structure Learning via Hypergradient Descent.
- [11] (2016)A review of relational machine learning for knowledge graphs. Proceedings of the IEEE104 (1), pp. 11–33. Cited by: footnote 2.
- [12] (2000)Nonlinear dimensionality reduction by locally linear embedding. Science290 (5500), pp. 2323–2326. Cited by: Introduction.
- [13] (2009)The graph neural network model. IEEE Transactions on Neural Networks20 (1), pp. 61–80. Cited by: Introduction.
- [14] (2000)A global geometric framework for nonlinear dimensionality reduction. Science290 (5500), pp. 2319–2323. Cited by: Introduction.
- [15] (2012)Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade, pp. 639–655. Cited by: A Brief Discussion of the Results.
- [16] (1990)An efficient gradient-based algorithm for on-line training of recurrent network trajectories. Neural computation2 (4), pp. 490–501. Cited by: Jointly Learning the Structure and the Model Parameters.
- [17] (2003)Semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the 20th International conference on Machine learning (ICML-03), pp. 912–919. Cited by: A Brief Discussion of the Results.